Weize Liu

I am a first-year Ph.D. student in Computer Science at the University of Maryland, College Park, advised by Prof. Furong Huang.
My research focuses on large language models (LLMs), particularly on improving models’ reasoning, agentic capabilities, reliability, and efficiency by developing advanced mid-training, post-training (SFT, RL) and data synthesis methods.
I am open to research collaborations; if you are interested in working together, please feel free to reach out via email.
News
| Jan 2026 | A paper was accepted to ICLR 2026! Thanks to all co-authors. See you in Brazil! Feel free to say hi and chat with me! |
|---|---|
| Sep 2025 | Started the Computer Science Ph.D. program at the University of Maryland, College Park. |
| Jun 2025 | Completed the M.Eng. in Computer Technology at Zhejiang University. |
Selected Publications
* Equal contribution
Only papers already published at top-tier conferences are shown here.
-
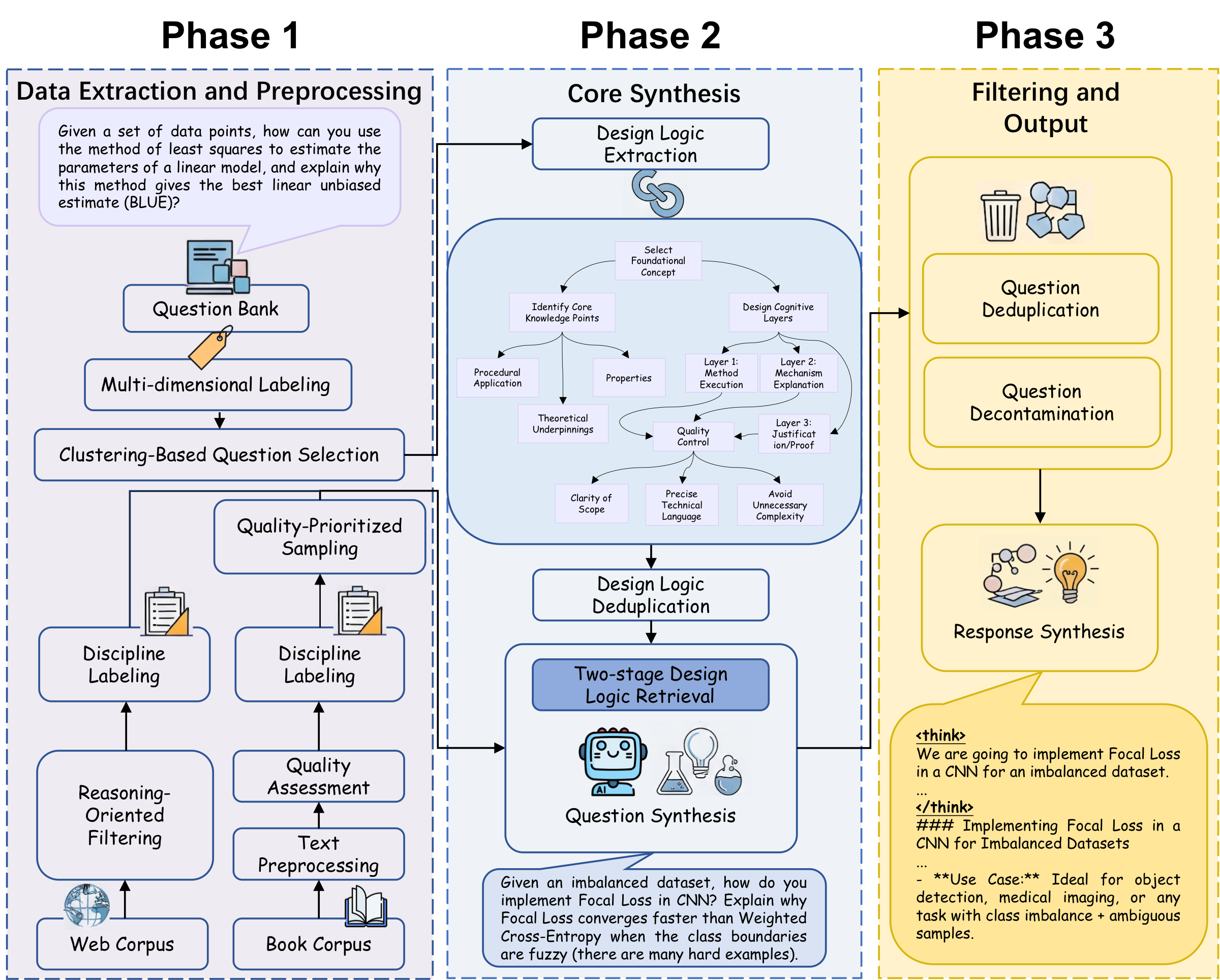 DESIGNER: Design-Logic-Guided Multidisciplinary Data Synthesis for LLM Reasoning
DESIGNER: Design-Logic-Guided Multidisciplinary Data Synthesis for LLM ReasoningShow details
- Post-training and even mid-training rely heavily on exam-style data, yet many low-resource disciplines still lack sufficient high-quality questions. Existing data synthesis methods face two major challenges: query-centric approaches are limited by seed-question coverage and model bias, while document-centric approaches lack control over question difficulty. Therefore, we propose DESIGNER: a DESIGN-logic-guidEd Reasoning data synthesis pipeline for synthesizing multidisciplinary reasoning questions from raw corpora.
- The central insight is the notion of "Design Logic", a form of reusable meta-knowledge that encapsulates how human experts transform knowledge points into complex exam questions. Design logic enables LLMs to generate new questions with the same complex reasoning patterns from entirely different source texts, with explicit control over difficulty, diversity, and types. We extracted over 120,000 Design Logics from filtered human-authored multidisciplinary question banks using LLMs.
- We designed a two-stage retrieve-and-generate mechanism (semantic similarity for coarse ranking followed by LLM-based fine ranking) to precisely match Design Logics with raw corpora that underwent our multi-dimensional labeling and filtering process, synthesizing two large-scale datasets spanning 75 diverse disciplines: DLR-Book (3.04 million questions from book corpora) and DLR-Web (1.66 million questions from web corpora).
- Data analysis shows that questions synthesized by our method exhibit significantly greater difficulty and diversity compared to existing datasets. A series of SFT experiments on the Qwen3 and Llama3 model families demonstrate that our data substantially enhances LLMs’ multidisciplinary reasoning capabilities, outperforming baseline datasets. Notably, applying SFT on the base versions of these models using only our dataset even yields performance surpassing their officially released post-trained final models.
-
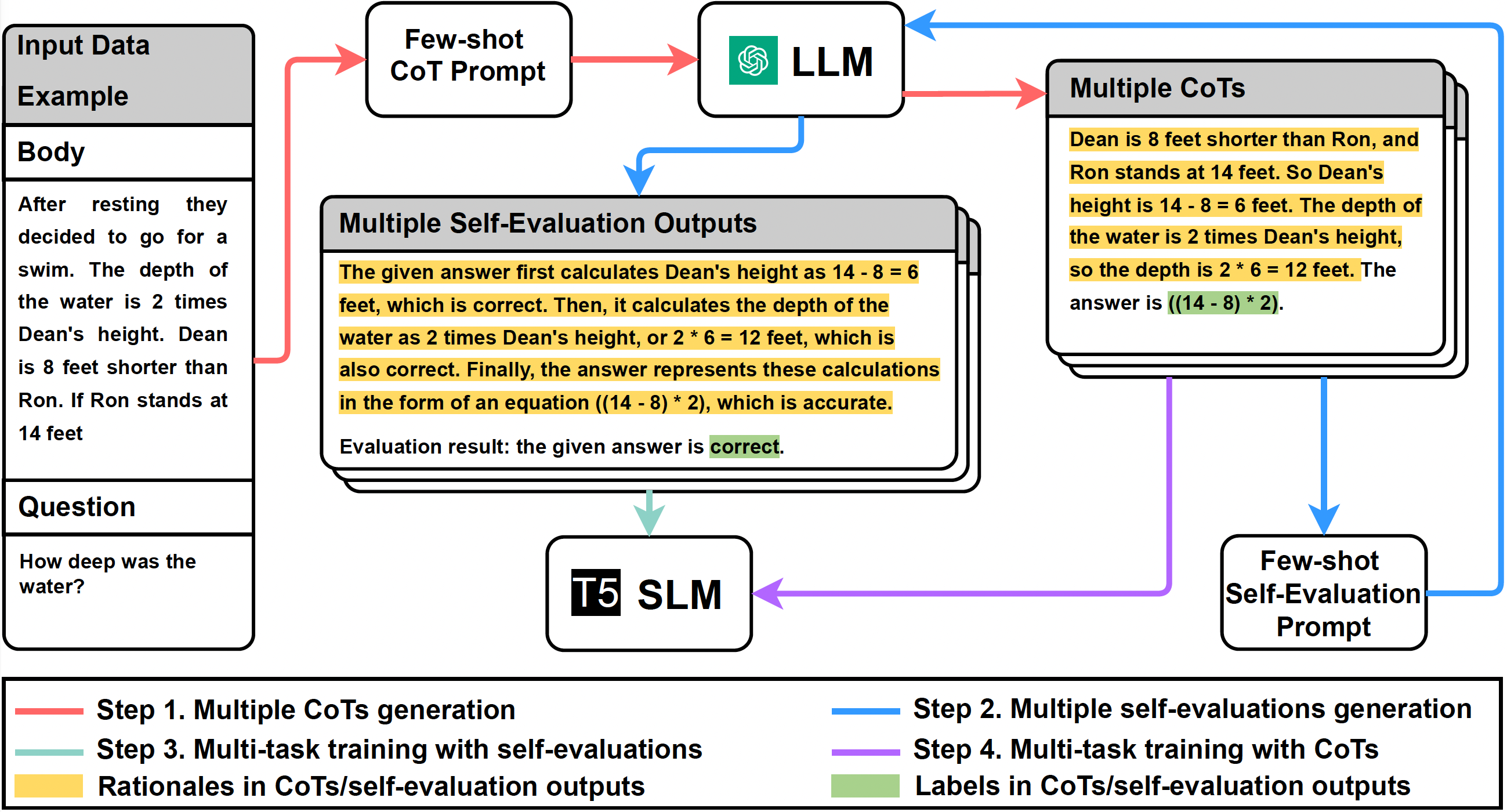 Mind’s Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models
Mind’s Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language ModelsShow details
- We proposed a novel data distillation (data synthesis) approach that distills the self-evaluation capability from LLMs into small language models (SLMs). By learning from the analysis and evaluation of CoT correctness, SLMs gain understanding of the potential reasons behind correct or incorrect reasoning, enabling deeper comprehension of problems and thus improving answer accuracy and reliability.
- To overcome the randomness and limitations of generated synthetic data, we further proposed distilling diverse chains of thought along with their corresponding multiple self-evaluations from LLMs, enabling SLMs to learn more comprehensive reasoning paths and thinking spaces of LLMs.
- Comprehensive experiments demonstrate that our method enables SLMs to successfully learn the self-evaluation capability and more comprehensive thinking of LLMs, significantly enhancing the performance and reliability of trained SLMs, and outperforming previous CoT distillation methods. This demonstrates that our method is essential for SLMs to achieve efficient, high-quality, and reliable reasoning, especially in resource-constrained environments.
-
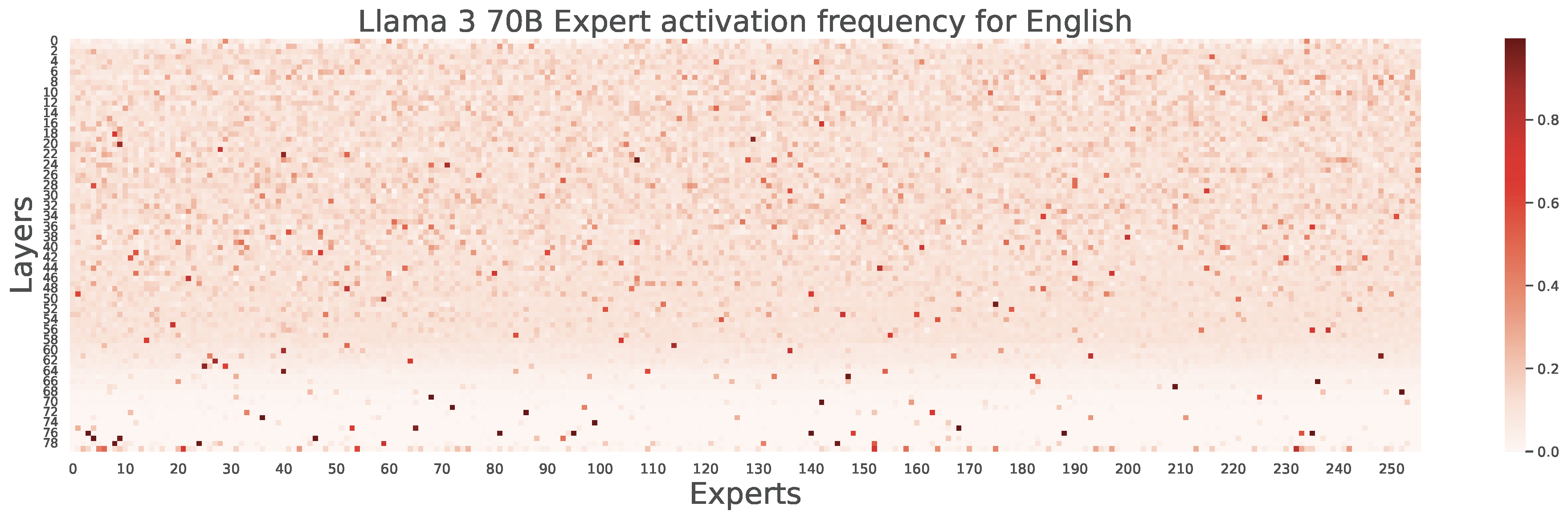 Unraveling Babel: Exploring Multilingual Activation Patterns of LLMs and Their Applications
Unraveling Babel: Exploring Multilingual Activation Patterns of LLMs and Their ApplicationsShow details
- To analyze the similarities and differences in internal neuron activities when LLMs process different languages, we designed a method to convert dense LLMs into fine-grained MoE architectures, and visually analyzed multilingual activation patterns within LLMs through expert activation frequency heatmaps.
- Through extensive experiments across different model families, model sizes, and variants, we analyzed the distribution of high-frequency activated neurons for different languages, the distribution of multilingual shared neurons, whether activation patterns of different languages relate to their language families, and the impact of instruction tuning on activation patterns.
- We further explored leveraging the discovered differences in expert activation frequencies to guide sparse activation and pruning during model inference. Experimental results demonstrate that our method significantly outperforms random expert pruning and even exceeds the performance of original unpruned models in some languages. Additionally, we find that configuring different pruning rates for different layers based on activation level differences yields better results.
-
 From Misleading Queries to Accurate Answers: A Three-Stage Fine-Tuning Method for LLMs
From Misleading Queries to Accurate Answers: A Three-Stage Fine-Tuning Method for LLMsShow details
- Users often submit inaccurate queries when using LLMs, sometimes containing misleading information. LLM responses are susceptible to misleading information in queries. We proposed a three-stage post-training fine-tuning method that trains LLMs to detect and correct misleading information in queries, improving the accuracy and robustness of LLM responses when facing queries containing misleading information, and reducing the negative impact of misinformation on the model.
- Specifically, the three stages include: (1) training LLMs to identify whether queries contain misleading information; (2) training LLMs to correct misleading information in queries using internal or external knowledge; (3) training LLMs to generate accurate and reliable answers based on corrected queries.
- To validate our method, we constructed two datasets containing misleading information. Additionally, our trained model detected that some questions in commonly used benchmarks also contain misleading information; removing these misleading questions significantly improves model accuracy, while our method-trained model maintains robust responses and higher performance regardless of whether the query contains misleading information.
- Experimental results across multiple datasets on different tasks demonstrate that our method significantly improves the accuracy and factuality of LLM responses, while enhancing LLMs’ hallucination detection capabilities and reducing hallucinations in model outputs, especially when queries contain misleading information.